

Reactive Model Correction: Mitigating Spurious Correlations in Natural Disaster Management

Dilyara Bareeva, PhD Candidate in Explainable AI at Fraunhofer HHI
Leila Arras, PhD Candidate in Explainable AI at Fraunhofer HHI
Jawher Said, Research Assistant in Explainable AI at Fraunhofer HHI
Artificial Intelligence (AI) has become a critical tool in natural disaster management, enabling real-time predictions, risk assessments, and decision-making. However, the effectiveness of AI models can be undermined by spurious correlations—where irrelevant features in the training data influence predictions. These shortcuts, often due to imperfections in training datasets, pose serious risks in high-stakes scenarios.
For instance, wildfire detection models might erroneously associate specific cloud patterns with fire presence, simply because such patterns coincided with fires in historical data. This results in false alarms, wasted resources, and reduced trust in the system. Addressing these biases is essential to ensure AI reliability.
Challenges in Correcting Spurious Correlations
Traditional methods for mitigating spurious correlations, such as model retraining [1] or global post-hoc corrections [2], have significant limitations. Retraining models is computationally expensive, especially for large datasets and models, and often requires access to the original training data. Meanwhile, global corrections—where all predictions are modified to suppress spurious features—can degrade the model's performance on "clean" samples. For example, suppressing features resembling clouds might also suppress valid indicators like smoke, reducing the model's ability to detect actual wildfires.
To overcome these challenges, researchers have introduced a more targeted and efficient approach: Reactive Model Correction [3].
Reactive Model Correction: A Targeted Approach
Reactive Model Correction selectively applies corrections only when specific conditions are met, minimizing collateral damage to the model's overall performance. Unlike traditional methods that suppress spurious correlations uniformly, this approach relies on context-sensitive interventions, informed by Explainable AI (XAI).
For example, a wildfire detection model using Reactive Model Correction would only suppress the influence of spurious cloud features if:
- A fire is predicted, and
- The specific cloud feature is detected and identified as influencing the prediction.
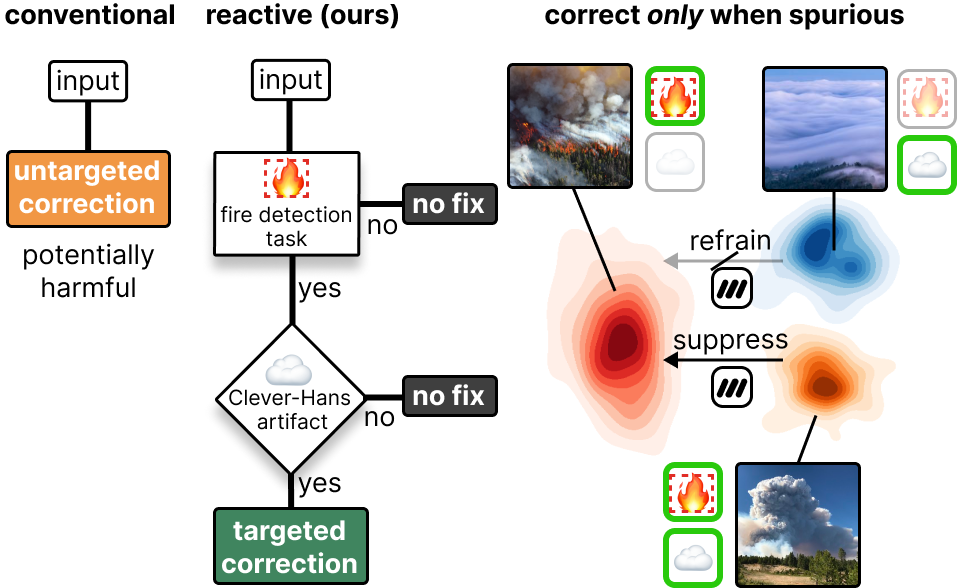
By focusing on specific predictions and conditions, Reactive Model Correction preserves the model's accuracy for unaffected samples, ensuring both robustness and precision.
Role of XAI in Reactive Model Correction
Explainable AI (XAI) methods offer a transparent view into the decision-making processes of AI models, enabling researchers and domain experts to identify when spurious features influence predictions. By clarifying the role of such features, XAI informs Reactive Model Correction, a strategy where corrective actions are conditionally applied to address specific scenarios without compromising overall model performance.
Key XAI techniques that enhance Reactive Model Correction include:
- Attribution Methods
Attribution techniques measure the relevance of specific features—such as image regions—to individual predictions [6, 7]. For example, Layer-wise Relevance Propagation (LRP) can reveal whether a wildfire detection model is overly influenced by irrelevant artifacts like sunsets, clouds, or vegetation, rather than valid indicators like smoke. - Concept-Based Methods
These methods detect the presence of spurious artifact concepts within a model’s representations and assess their influence on predictions [4, 5]. For instance, they can identify specific cloud shapes or vegetation patterns that a model might mistakenly associate with wildfires or floods. - Strategic Clustering
By examining hidden activations and attribution patterns, a strategic clustering groups predictions based on similar decision-making strategies. Clusters dominated by spurious correlations can be identified and flagged for correction [8]. For example, predictions influenced by irrelevant cloud patterns can be separated from those based on critical features like fire boundaries or smoke plumes.
These XAI techniques provide actionable insights, enabling Reactive Model Correction to selectively target and suppress spurious correlations while preserving the model’s ability to make accurate and reliable predictions.
Conclusion
Reactive Model Correction represents a paradigm shift in addressing spurious correlations in AI models, particularly in critical applications like natural disaster management. By leveraging XAI to enable targeted, context-sensitive interventions, this approach ensures that AI systems remain trustworthy and effective, even in the face of complex and high-risk scenarios.
With Reactive Model Correction, we can build more reliable AI systems that support accurate decision-making, saving lives and resources in disaster response.
References
- Dreyer, M., et al. "From hope to safety: Unlearning biases of deep models via gradient penalization in latent space." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 38. No. 19. 2024.
- Anders, C. J., et al. "Finding and removing clever hans: Using explanation methods to debug and improve deep models." Information Fusion, 77 (2022): 261-295.
- Bareeva, D., et al. "Reactive Model Correction: Mitigating Harm to Task-Relevant Features via Conditional Bias Suppression." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. June 2024.
- Pahde, F., et al. "Navigating Neural Space: Revisiting Concept Activation Vectors to Overcome Directional Divergence." arXiv preprint arXiv:2202.03482.
- Vielhaben, J., et al. "Beyond scalars: Concept-based alignment analysis in vision transformers." arXiv preprint arXiv:2412.06639.
- Bach, S., et al. "On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation." PLOS ONE, 10.7 (2015): e0130140.
- Achtibat, R., et al. "From attribution maps to human-understandable explanations through concept relevance propagation." Nature Machine Intelligence 5, 1006-1019 (2023).
- Dreyer, M., et al. "Understanding the (extra-)ordinary: Validating deep model decisions with prototypical concept-based explanations." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2024.